구현에 들어가기 앞서 아키텍쳐부터 확정짓고 가기로 했다.
우선 mermaid 문법을 모르기에.. GPT를 써서 빠르게 시퀀스 다이어그램부터 완성했다.
사용자 -> FastAPI 까지의 시퀀스와 FastAPI 내부의 시퀀스를 나누었다.
우선은 사용자 -> FastAPI 까지의 시퀀스 다이어그램이다.

개인 프로젝트임에도 욕심이 가득한게 보인다.
특정 도메인에 내 취향이 잔뜩 담긴 프로젝트지만 이왕 하는거 실 서비스에 가깝게 만들어 보려고 한다.
우선 리버스 프록시 역할을 할 미들웨어가 필요했다.
단순 react - FastAPI 연결을 했다가는 예상치 못한 무수한 요청에 무의미한 API 호출로 지갑이 거덜날까 무서워, Spring으로 미들웨어를 구축하며, 세션 베이스 사용자 인증 로직도 추가하기로 했다. 물론 id/password는 MySql 로 관리를 하려고 한다.
JWT를 쓸까 했지만, 세션 만료나 검증이 되긴 했지만 중간에서 탈취당할 가능성도 있고, 메모리 누수 가능성이 있어서
Redis 사용으로 해당 리스크를 회피하려고 한다.
근데 아마 JWT 로직도 만들긴 할것같다. 한번 구현 난이도나 차후 유지보수성 관련해서 직접 보고싶기 때문이다.
전체 아키텍쳐 흐름을 잡기 위한 목적으로 만들었기 때문에 redis의 key나 URL method는 언제든 변경될 가능성이 높다.
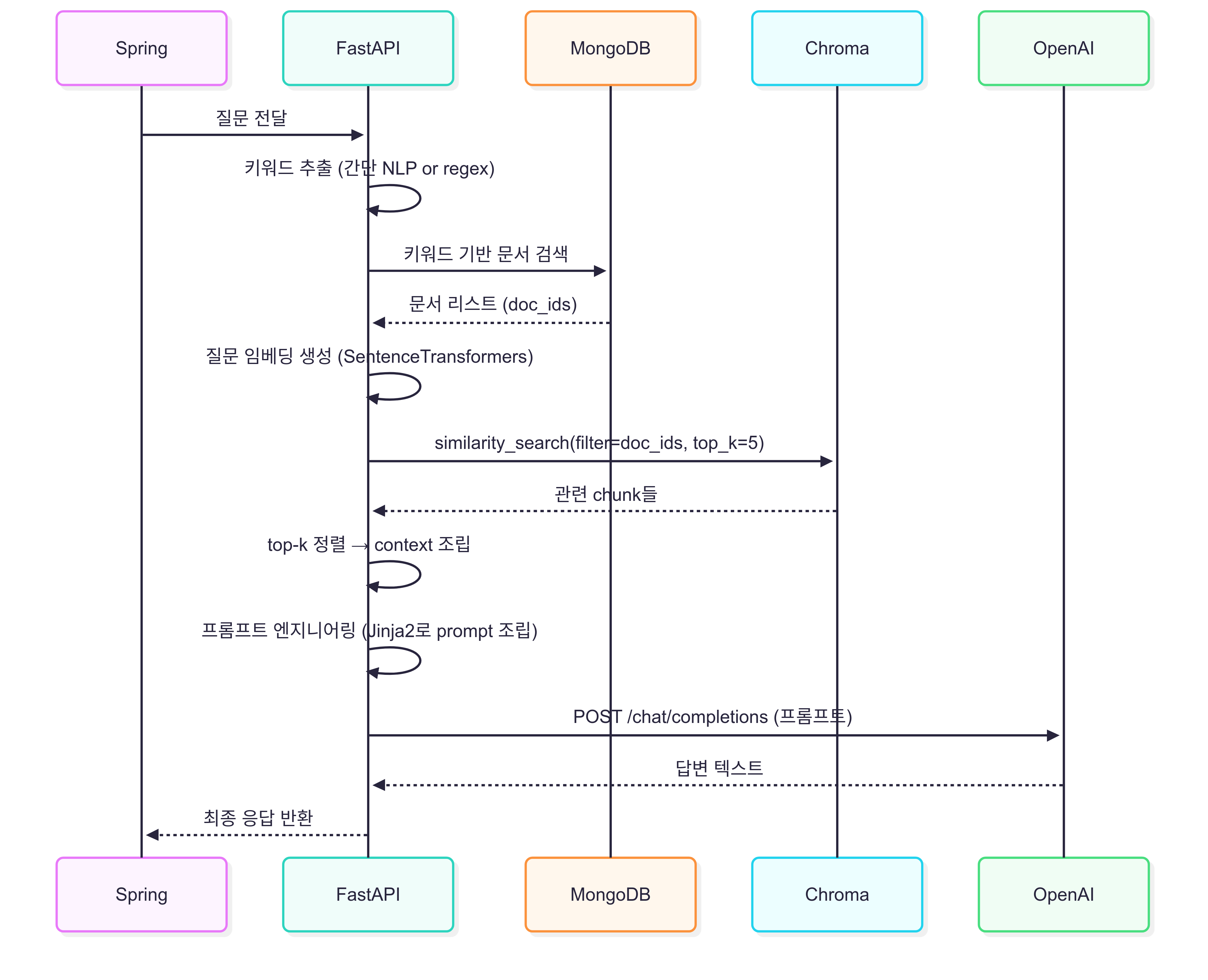
다음은 FastAPI 내부 로직 시퀀스 다이어그램이다.
우선은 정규표현식으로 키워드를 추출해서 MongoDB에서 키워드 기반 서치를 해서! 조금이라도 성능 + 정확도 이점을 보려고 한다.
MongoDB 스키마는
{
"_id": ObjectId("..."), # Mongo 고유 ID
"doc_id": "abc123def456", # Chroma 등록용 고유 ID (초기 벡터화 진행 시 입력)
"title": "길드의 접수원인데, 야근이 싫어서 보스를 혼자 토벌하려고 합니다/애니메이션", # 사용자 or 크롤러 기반 제목 ✅
"url": "https://namu.wiki...",
"segments": [ # 본문을 문단 단위로 분할한 리스트
"그리고 2025년 3월 마지막주 편성의 경우...",
"스토리는 원작부터가 개연성 부분에서 저평가를 받은 ...",
...
],
"keywords": ["2025년1분기애니메이션", ...], # 키워드 기반 Mongo 필터링용
"vectorized": True, # Chroma에 벡터 등록 완료 여부
"created_at": "2000-00-23T12:34:56Z" # 삽입 시각
}
이런식으로 구성했다.
vertorized 필드를 만든 이유는 처음에 데이터 수집을 할 때, 일일이 json -> insert -> 벡터화 과정이 번거로와서
json 추출이 아닌 바로 insert를 하고, 수집 이후 일괄로 해당 필드가 false인 애들만 싹 다 긁어다가 벡터화 해서 doc_id 필드 추가하고 벡터화 한 값들은 바~로 Chroma에 집어넣는 파이프라인을 설계했다.
이것도 faiss -> chroma 바꾼 이유 중 하나인데, 매번 벡터화 하고 벡터 디비에 넣고 하기가 로컬 환경에선 좀 부담되고,
물론 faiss도 벡터화 해도 인덱싱 한거를 저장할수가 있긴 한데 일단은 스토리지 베이스인 애로 실험을 해보고 성능이나 추가 기능이 필요하면 그때 faiss 혹은 다른 벡터 DB를 고려하지 않을까 싶다.
아무튼 이제 정규표현식을 통해 유저 쿼리에서 키워드 추출 해가지고 몽고 DB에 keyword 필터링 걸어가지고 doc_id 추출해서
이 doc_id를 베이스로 Chroma를 사용해서 유사도 검색을 진행할 것이다. 일단은 Top-5를 잡았는데 이 부분은 실제로 몇번 실험해 보면서 줄이거나 늘리거나 할 듯 싶다.
유사도 검색으로 추출한 chunk들과 유저 쿼리를 통해 프롬프트를 만드는 것 까지가 주 된 로직이라고 할 수 있다.
프롬프트는 jinja2로 여러가지 쪄놓긴 했는데 유기적으로 알잘딱 적절한 프롬프트 고르는 기능까지 넣어보고 싶긴하다.
이후는 openai API 혹은 로컬에 LLama 설치해서 서빙 후 결과 보고 top-k 든 머든 해서 튜닝 하고 좀 맛있는 답변 나오나 봐야한다. 이 부분도 된다면 두가지 다 구현하지 않을까 싶다. 왜냐면 단순 openai API 서빙도 중요하지만 파인튜닝된 LLM을 서빙할수도 있으니 유도리 있게 바꿔낄 수 있게 잘 구현해야겠다.
아키텍쳐는 진짜 맛있게 짠것같다. 슬... 구현 드가야겠지?
'개인 프로젝트' 카테고리의 다른 글
| LLM + RAG 프로젝트 [3.1] 프론트 - 미들웨어 인증 로직 수정 (2) | 2025.08.19 |
|---|---|
| LLM + RAG 프로젝트 [4] 데이터 수집 (0) | 2025.08.08 |
| LLM + RAG 프로젝트 [3] Reverse Proxy 구성 (7) | 2025.07.29 |
| LLM + RAG 프로젝트 [1] (1) | 2025.06.18 |
| LLM + RAG 프로젝트 시작 [0] (0) | 2025.06.15 |
