optuna 사용해서 다양한 경우의수 시도해 본 결과

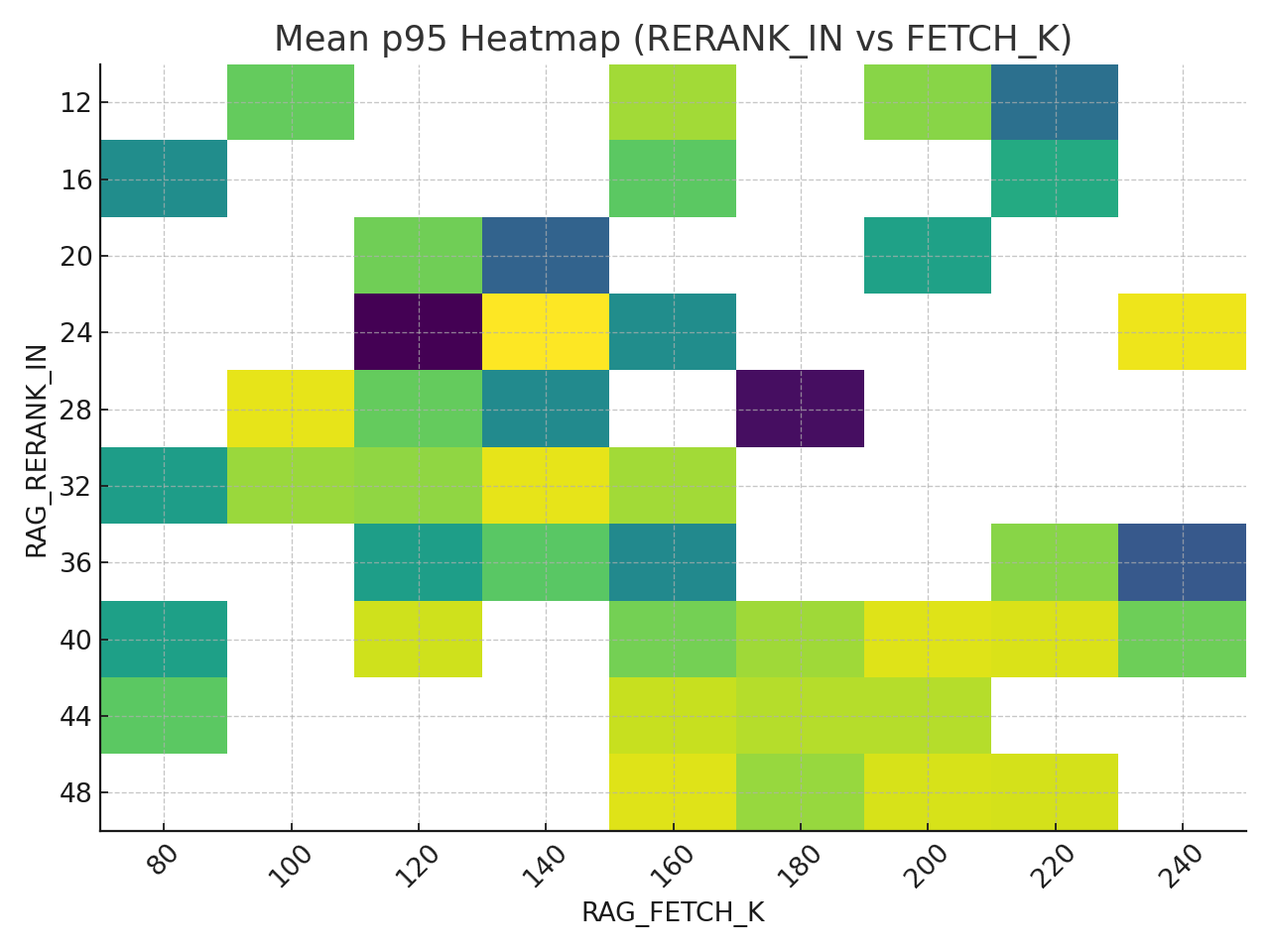
fetch_k 는 120정도가 내 환경에선 베스트라고 판단된다.
120 전후로 p95가 15%정도 상승하고 Rerank와 병목이 일어나며 p95가 치솟는걸 확인할 수 있었다.

MMR을 켰을 때 p95가 두배정도 튀긴 하지만 정확도면에서 압살하는 모습을 보였다.
0.52 자체도 막 맛있는 수치는 아니긴 하다.
이부분들을 해결하기 위해서 현재
BM25를 도입하여 단순 chroma 서치에서 하이브리드로 교체하고
튜닝 방향성을 MMR을 키고 MMR 가중치를 0.7~0.8로 주고 Fetch_k는 120 고정, 이후 다른 파라미터들을 수정하여 p95를 줄이는 쪽으로 잡고 진행중이다.
위에서 유의미한 결과가 나온다면 이제 recall값, nDCG 값 즉 얼마나 잘맞췄는가 이쪽에 집중할 예정이다.
일단 초기에 recall과 nDCG값이 0.3~0.35 주변에 분포했었는데 성능 개선을 하다보니 이 부분이 0.4~0.55 까지 올라왔다.
점차 최적의 파라미터 대역으로 스코프가 줄어드는 느낌이라 기분이 좋다.
p95 - rerank 쪽 병목이 해결되면 e2e 테스트로 튜닝없던 쌩 깡통 상태의 LLM 응답과 현재의 응답 차이도 확인할 예정이다.
아 그리고 nDCG, mmr_k 의 설명은 아래와 같다. (GPT에게 짬때렸다.)

1) mmr_k — MMR에서 “다양성 창”의 크기
정의: MMR(Maximal Marginal Relevance) 단계에서 뽑아낼 문서(또는 청크) 수. 최종 반환 개수 k와 다르다.
- 관계: k ≤ mmr_k ≤ pre_k (여기서 pre_k는 MMR에 들어갈 후보군 크기)
- 역할: mmr_k가 클수록 다양성↑(중복↓) 이지만 계산량↑ ⇒ p95(지연)↑.
MMR 목적함수(의미론):

- SS: 이미 선택된 문서 집합
- λ∈[0,1]\lambda\in[0,1]: 관련성 vs. 다양성 가중치
- 이 선택을 mmr_k번 반복해 랭킹 리스트를 만든다.
튜닝 가이드(요점만):
- k가 8~9라면, mmr_k는 24 ~ 34 ( ≈ 34×k) 범위가 안전.
- 너무 작으면 다양성 부족으로 dup↑, 너무 크면 **p95↑**가 발목을 잡는다.
- 실측 기준(본 데이터셋): 30 ± 4가 균형점. 품질 최우선이면 34, 지연 중시면 26~29.
체크리스트:
- 제약을 코드 레벨에서 강제: mmr_k ≤ pre_k ≤ fetch_k
- λ(람다) 효과: λ↑(예: 0.8) → 관련성 비중↑, 일반적으로 nDCG/MRR/Recall이 소폭 좋아지지만, p95는 다소↑.
2) nDCG — 정답을 “위로” 얼마나 올렸는가
정의: normalized Discounted Cumulative Gain, 0~1. 상위에 정답을 배치할수록 점수가 크게 오른다.
- DCG:
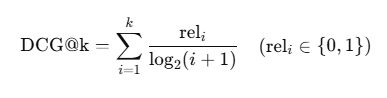
- nDCG:

여기서 IDCG는 정답을 이상적으로 위쪽에 몰아넣었을 때의 DCG.
예시(이진 관련성, k=5):
1위와 4위가 정답이면

정답 2개를 1·2위에 뒀을 때

왜 dup(중복)과 연결되나?
nDCG는 중복 자체를 직접 패널티 하진 않지만, 중복이 많으면 정답이 아래로 밀림 → DCG가 줄고 nDCG↓.
해석 요령:
- nDCG는 상위 정답 집중도를 본다. 같은 Recall이라도 정답을 1~3위에 몰면 nDCG↑.
- mmr_k를 적절히 키워 중복을 줄여 상위 포지셔닝을 돕는 것이 실전 핵심.
3) 실전 권장값(현업 감각)
- Balanced 운영(권장):
k=9, MMR on / λ=0.8, mmr_k≈30, pre_k=80, fetch_k=120, rerank_in≈30, title_cap=2 - Quality-first(예산 있을 때):
k=10, MMR on / λ=0.7, mmr_k=34~40, rerank_in≈20, fetch_k=120~140
→ nDCG 소폭↑ 가능하지만 p95/dup 관리 필요.
4) 흔한 함정
- mmr_k 과도↑: nDCG 소폭↑라도 p95 급증으로 체감 악화. 운영에선 득보다 실.
- fetch_k 과도↑: 후보가 늘수록 dup↑, 리랭크 비용↑, 품질 이득은 미미.
- rerank_in 과도↑: 리랭커가 떠안는 수가 커져 p95 병목. 보통 28~32가 상한선.
- MMR off로 우승한 조합: 리랭크에 과의존 → dup↑, p95↑. 운영값으로 부적합한 경우가 많다.
5) 미니 유틸(검증용 코드)
import math
def ndcg_at_k(retrieved, gold, k):
G = {g.lower() for g in gold}
rels = [1.0 if (r.lower() in G) else 0.0 for r in retrieved[:k]]
dcg = sum(rel / math.log2(i+2) for i, rel in enumerate(rels))
idcg = sum(1.0 / math.log2(i+2) for i in range(min(k, len(G))))
return dcg / idcg if idcg > 0 else 0.0블랙박스처럼 쓰지 말고, 실측 분포를 한 번은 직접 돌려서 nDCG/Recall/dup/p95의 상관을 눈으로 확인하라.
TL;DR
- mmr_k = 다양성 창 크기. k가 8~9면 30 ± 4가 안전. 과하면 p95 터진다.
- nDCG = 상위 정답 배치 점수. 중복이 정답을 아래로 밀면 nDCG가 떨어진다.
- 운영 기본은 MMR on / λ≈0.8 / mmr_k≈30 / rerank_in≈30 / fetch_k≈120 / title_cap=2.
- 숫자 한 끗 올리자고 p95를 두 배로 만들지 마라. 사용자 체감이 최우선이다.
'개인 프로젝트' 카테고리의 다른 글
| LLM + RAG 프로젝트 [10] E2E 완성 (0) | 2025.09.11 |
|---|---|
| 도자기 빗는게 이런 느낌일까 (0) | 2025.09.11 |
| LLM + RAG 프로젝트 [8] RAG 튜닝 진행중... (0) | 2025.09.08 |
| LLM + RAG 프로젝트 [7] 타율 0 해결을 위한 튜닝 (0) | 2025.09.04 |
| LLM + RAG 프로젝트 [6] End to End MVP 완성 (4) | 2025.09.01 |
