workbench의 import wizard 를 사용하면 너무 오래 걸리는 문제때문인지 row를 날려먹는다.
콘솔에서 load data를 사용하는것이 가장 빠르다고 하여 시도해 본 것들을 정리해 보겠다.
1. 환경변수 등록.
콘솔에서 mysql 명령어가 작동하지 않았다.
installer로 설치하는 과정에 path관련 항목이 있길래 당연히 나는 환경변수 편집이 되어 있을 줄 알았다.
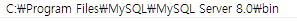
windows 답게 안되어있는걸 보니 머리에 열이 조금 찼다.
이렇게 MySQL Sever bin 폴더를 환경변수 path에 넣어주니 mysql 명령어가 cmd에서 잘 작동했다.
2. workbench connection 수정
콘솔에서 아무리 local infile =1 을 줘도 workbench에는 적용이 안되는걸 보니 더욱 열이 찼다.

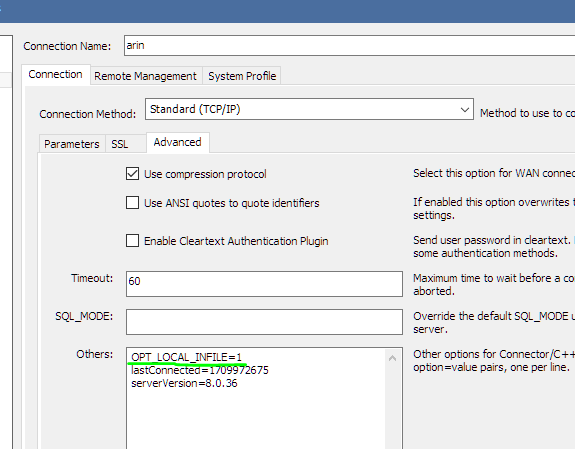
이렇게 손수 추가해 주었다.
3. 콘솔 접속을 root로 하고 load data 실행
cmd에서
mysql --local-infile=1 -u root -p 를 하고 비밀번호를 입력한 후 load data를 실행했다.
이럼에도 오류를 내뿜어서 뇌가 녹아버릴 것만 같았다.
그래도 아예 명령어가 안듣고 connection 오류가 났던것보다는 나았다...
첫번쨰로 load data 쿼리문을 한번에 복사 붙여넣기 해서 syntax error가 발생했고
두번쨰로 디렉토리를 찾지 못해 오류가 발생했다.

디렉토리 오류는 workbench에서도 발생했다.

구글링 결과 디렉토리 구분을 \가 아니라 / 를 사용해야 한다고 한다.
에러코드를 보면 파일 경로에 역슬래시가 다 날라가있다.
4. load data 경로에서 \를 /로 교체

아주 진행이 잘 되는 모습이다.

다른 테이블에도 똑같이 workbench에서 load data를 하였는데
데이터셋이 10만, 100만 단위가 아니라서 그런가 속도 차이가 거의 없는 모습이다.
미리 테이블을 만들어야 하는게 조금 많이 매우 문득 새삼 귀찮지만 load data 쿼리문에 익숙해지니까
편하긴 한 것 같다.

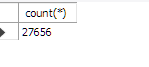
컬럼도 제대로 들어왔고 레코드 갯수도 원본 데이터와 같은것을 확인했다.
pandas의 read_csv가 매우 편했었다는걸 다시한번 깨달았다.
재부팅 하거나 업데이트 했을 때 지혼자 또 환경변수나 세팅 바뀌어서 안될까봐 두렵다...

'data > sql' 카테고리의 다른 글
| jupyter notebook에서 sql 쓰기 (1) | 2024.03.19 |
|---|---|
| Sql 이진 데이터 (2) | 2024.03.06 |
| Mysql 8.0 Workbench로 로컬 테스트 환경 구축 (1) | 2024.03.05 |
| SQL Join (1) | 2024.03.05 |
| sql 문법 정리 2 (1) | 2024.03.04 |



