두번째로 도전했던 문제였다.
첫번째로 도전한건 건강상태를 보고 흡연 여부를 분류하는 문제였는데, 이건 분류모델의 기능, 각종 메소드와 손실함수 평가지표가 뭐하는녀석인지도 모른 채 퍼셉트론만 잔뜩 만들어 진행했었다.
그 다음으로 진행한 space titanic 문제는 그래도 matric이 뭘 계산하는지 과적합 났을때 어떻게 해야하는지 스케일러는 뭘 써야하는지 고민해보고 엄청 복잡한 딥러닝 모델도 만들어보고 쉽고빠른 랜덤포레스트 모델도 사용해 보았다.
결측치를 밥먹듯이 삭제하는게 아니라 데이터 분포를 살펴보고 채워넣는 방법도 배웠다.
원 핫 인코딩을 진행했더라면, ordinary 인코딩 할 때 인코딩 된 숫자를 조금 더 신경썼더라면 좋았겠지만
df_train["RoomService"].fillna(0, inplace=True)
df_train["FoodCourt"].fillna(0, inplace=True)
df_train["ShoppingMall"].fillna(0, inplace=True)
df_train["Spa"].fillna(0, inplace=True)
df_train["VRDeck"].fillna(0, inplace=True)
df_train["HomePlanet"].fillna("Earth", inplace=True)
df_train["Destination"].fillna("TRAPPIST-1e", inplace=True)
df_train["CryoSleep"].fillna(0, inplace=True)
df_train["VIP"].fillna(0, inplace=True)
df_train["Age"].fillna(29, inplace=True)
df_train.loc[df_train["Destination"]=="TRAPPIST-1e", "Destination"]=0
df_train.loc[df_train["Destination"]=="55 Cancri e", "Destination"]=1
df_train.loc[(df_train["Destination"] != "55 Cancri e") & (df_train["Destination"] != "TRAPPIST-1e"),"Destination"]=2
df_train.loc[df_train["HomePlanet"]=="Earth", "HomePlanet"]=0
df_train.loc[df_train["HomePlanet"]=="Europa", "HomePlanet"]=1
df_train.loc[df_train["HomePlanet"]=="Mars", "HomePlanet"]=2scikit learn에 imputer 메소드가 있는걸 최근에야 알아서 이 당시에는 하드코딩으로 결측치 처리를 진행했다 ㅋㅋㅋㅋㅋ
인코딩도 encoder 사용했더라면 조금 더 코드가 깔끔했을텐데~ 싶다.
처음 흡연여부 이진분류 모델에서는 랜덤포레스트의 존재는 알았지만 어떻게 쓰는지, 어떤식으로 작동하는지도 몰랐어서 space titanic 문제를 진행할 때도 앙상블 모델을 만들어보고 써보고 싶은데 방법을 몰랐어서 임의로 연관성 있다고 생각하는 컬럼들을 조합해서 4개의 input을 가지는 앙상블 모델을 직접 층을 쌓아 만들었다.
def arin_4_elu():
nadam = tf.keras.optimizers.Nadam(learning_rate=0.001)
input_to = Input(shape=(3,))
x = Dense(256, activation = 'elu', kernel_initializer=initializer1)(input_to)
x = BatchNormalization()(x)
x = Dropout(0.3)(x)
input_rs = Input(shape=(5,))
y = Dense(512, activation = 'elu', kernel_initializer=initializer1)(input_rs)
y = BatchNormalization()(y)
y = Dropout(0.2)(y)
input_a_v = Input(shape = (2,))
z = Dense(32, activation = 'elu', kernel_initializer=initializer1)(input_a_v)
z = BatchNormalization()(z)
z = Dropout(0.55)(z)
input_cry = Input(shape=(8,))
i = Dense(1024, activation = 'elu', kernel_initializer=initializer1)(input_cry)
i = BatchNormalization()(i)
i = Dropout(0.2)(i)
sum_xyz = layers.Concatenate()([y, x, z, i])
s = BatchNormalization()(sum_xyz)
s = Dense(1024, activation = 'elu', kernel_initializer=initializer1)(s)
s = Dropout(0.5)(s)
s = Dense(1024, activation = 'elu', kernel_initializer=initializer1)(s)
s = Dropout(0.5)(s)
s = Dense(512, activation = 'elu', kernel_initializer=initializer1)(s)
s = Dropout(0.5)(s)
s = Dense(512, activation = 'elu', kernel_initializer=initializer1)(s)
s = Dropout(0.5)(s)
output = layers.Dense(1, activation = 'sigmoid', kernel_initializer='glorot_normal')(s)
arin4_elu = Model(inputs = [input_to, input_rs, input_a_v, input_cry], outputs = output, name = "ARIN4_elu")
arin4_elu.compile(optimizer=nadam, loss='binary_crossentropy', metrics=['accuracy'])
arin4_elu.summary()
return arin4_elu
캐글 submit 점수 0.8의 벽을 노드 수 조정하고 활성함수 다른거 사용해보고 he 초기화 사용해보고 아무리 dropout을 바꿔도 넘지 못했었는데 위의 모델 형태에서 노드수를 조금 더 추가하고 dropout을 출력층에 가까워질수록 줄였더니 넘었었다.
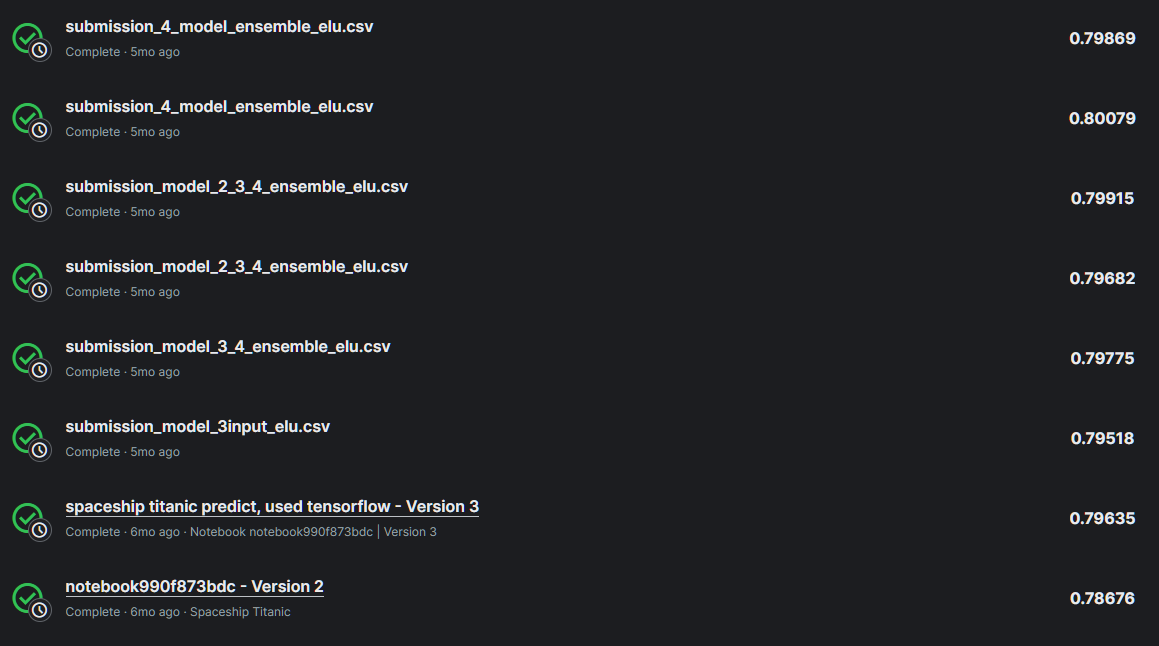
여기에 한번 도전해보고 바로 프로그래머스 데이터분석 데브코스 수강 준비하느라 진행하지 못했었지만

랜덤포레스트 모델의 탬플릿 하이퍼파라미터 사용한 것 보다 점수가 높게 나와 0.8의 벽을 넘었다는게 지금 생각해도 정말 기분이 좋다.
비록 이걸 진행하면서 다른 모델들을 사용해보고 하이퍼파라미터를 조정해본건 아니지만
tensorflow 함수형 api 사용에 꽤 익숙해졌고, xgboost의 존재를 이 때 처음 알게 되었다.


0.8의 벽을 넘지 못해 매우매우매우 복잡하게 만들었던 모델을 시각화 한 것인데,
로컬환경에서 돌렸을 때 컴퓨터에서 비행기 날라가는 소리와 프리징이 발생해서 빠르게 멈추고 캐글 노트북에서 진행했던 기억도 있다. 물론 epoch 20~30 넘어가기전에 과적합이 나버렸지만 그래픽카드의 엄청난 수요의 이유를 다시한번 깨달았다.
또한 머신러닝 프로젝트를 진행할 때 반드시 딥러닝을 사용하고 복잡하게 만드는게 다가 아니라는것도 깨달았다.
최대한 가볍게 해결하는것이 베스트라고 생각되었다.
두달정도를 cuda 설치하고 1070ti 혹사시켰었다. nlp, rnn, lstm같은 딥러닝 선발대 기술은 사용해보지 못했지만 여러모로 깨닫게 된게 많았던 문제였다.
'python > MLDL' 카테고리의 다른 글
| GPT에게 자연어처리 배우기(문자열 전처리) (2) | 2024.05.24 |
|---|---|
| GPT에게 자연어처리 배우기(모델 구현) (0) | 2024.05.24 |
| GPT통해서 Metric 컨닝페이퍼 만들기 (0) | 2024.04.26 |
| 캐글 Regression with an Abalone Dataset 도전 (3) (1) | 2024.04.26 |
| 캐글 Regression with an Abalone Dataset 도전 (2)(클러스터링 실험) (0) | 2024.04.25 |


