
타겟변수의 훈련데이터셋의 고유한 속성이 3개임을 파악했다.
model_name = 'huawei-noah/TinyBERT_General_4L_312D'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = TFBertModel.from_pretrained(model_name, from_pt=True)
def get_embeddings(texts, tokenizer, model, batch_size=32, max_length=512):
embeddings = []
for i in tqdm(range(0, len(texts), batch_size), desc="Generating Embeddings"):
batch_texts = texts[i:i + batch_size]
inputs = tokenizer(batch_texts, return_tensors='tf', truncation=True, padding='max_length', max_length=max_length)
outputs = model(inputs)
cls_embeddings = tf.gather(outputs.last_hidden_state, [0], axis=1)
embeddings.append(cls_embeddings)
return tf.concat(embeddings, axis=0)
embeddings = get_embeddings(texts, tokenizer, model)
embeddings = embeddings.numpy()
토큰화와 임베딩 진행했다.
원래 batch_size 16, max_length 1024로 주고 진행하였는데 비용소모가 너무 크고
(길이수 확인해봐야할듯)
num_clusters = 3
kmeans = KMeans(n_clusters=num_clusters, random_state=42)
kmeans.fit(embeddings)
labels = kmeans.labels_
data = pd.DataFrame({'text': texts})
data['cluster'] = labels우선은 위에서 타겟변수의 속성이 3개임을 확인했기에 기본적인 클러스터링으로 k를 3으로 주고 k-means 클러스터링을 진행했다.
임베딩 차원이 312개 정도 되었는데 이 많은 변수들을 클러스터링 한 결과를 시각화하여 확인하기에는 비효율적이고 가시성도 떨어진다고 판단하여 PCA 진행했다.
pca = PCA(n_components=2)
reduced_embeddings = pca.fit_transform(embeddings)
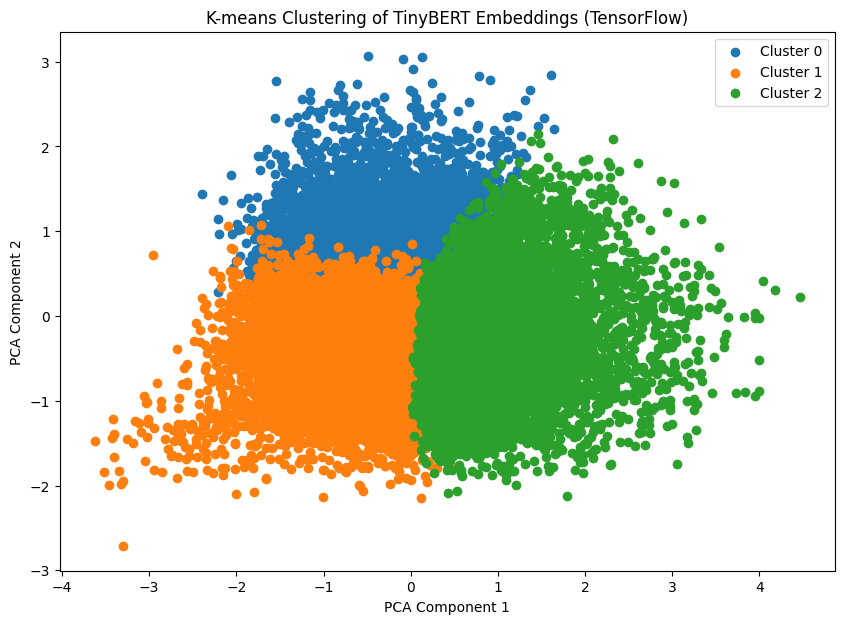
시각화 했을 때 클러스터를 가장 쉽게 표현할 수 있게 2개의 주성분으로 나누어 진행했다.
겹쳐있는 부분이 꽤 있지만 구분선은 명확해 보인다.
이제 클러스터링, PCA 결과를 가지고 다중분류 모델을 만들면 될 것 같다.
우선은 클러스터링, PCA를 진행하지 않은걸로 다중분류 모델을 먼저 만들어 보고, 그 다음으로 클러스터링과 PCA를 진행한 데이터를 input으로 사용해볼 것이다.
의문이 드는것은
첫째로 이런 고차원 데이터, 토큰화된 데이터를 트리기반 모델의 input으로 사용해도 성능이 괜찮게 나올까? 이고
두번째로 클러스터링과 PCA 진행한걸 굳이 다시 모델에 집어넣지 않아도 되지 않을까? 이다.
실험을 해봐야 할듯.
클러스터링과 PCA의 결과는 모델에 집어넣으면 성능이 하락한다는걸 최근 프로젝트를 통해 배웠기에 진행하지 않았다.
그래서 통째로 토큰화된 데이터를 일단 transformers tiny bert을 파인튜닝 해서 학습시켜보기로 했다.
사용법 자체는 xgboost나 scikit learn과 별 차이가 없었다.
model = TFBertForSequenceClassification.from_pretrained(model_name, num_labels=3, from_pt=True)TFBertForSequenceClassification.from_pretrained() 부분이 그간 xgb를 쓰거나, randomforest를 썼던 부분이었다.
이렇게 tiny bert모델을 파인튜닝해서 자연어처리의 대략적인 전처리, 모델 학습, 평가를 익혀보려 했지만
X_train, X_test, y_train, y_test = train_test_split(input_ids, labels, test_size=0.2, random_state=42)
train_masks, test_masks = train_test_split(attention_masks, test_size=0.2, random_state=42)학습데이터와 테스트 데이터로 나누는 과정에서 슬라이스 관련해서 오류가 발생했다.
labels 변수가 integer가 아닌 object, 문자열로 이루어져 있어서 분리가 제대로 되지 않는가 싶어 원핫인코딩을 진행했다.
train_target_encoded = pd.get_dummies(train_df["author"], columns=["author"])
train_target_encoded = train_target_encoded.astype(int)유니크한 값이 3개뿐이라 판다스의 get_dummies 사용해서 빠르게 진행하고 다시 시도해봤다.

아...
def encode_texts(texts, tokenizer, max_length=128):
return tokenizer(texts, padding=True, truncation=True, max_length=max_length, return_tensors='tf')
inputs = encode_texts(texts, tokenizer)
input_ids = inputs['input_ids']
attention_masks = inputs['attention_mask']이런 코드로 인코딩을 진행했는데 과정에서 길이가 부족해서 none값이 들어가있는 것 같다.
train_test_split 사용 자체가 잘못된 것 같아 리서치가 더 필요해 보인다.
train_test_split이 tensor를 지원하지 않는 이유라고 한다.
inputs = encode_texts(texts, tokenizer)
input_ids = inputs['input_ids'].numpy() # numpy 배열로 변환
attention_masks = inputs['attention_mask'].numpy()
# 학습 데이터와 테스트 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(input_ids, labels, test_size=0.2, random_state=42)
train_masks, test_masks = train_test_split(attention_masks, test_size=0.2, random_state=42)
# 분할된 데이터를 다시 텐서로 변환
X_train = tf.convert_to_tensor(X_train)
X_test = tf.convert_to_tensor(X_test)
y_train = tf.convert_to_tensor(y_train)
y_test = tf.convert_to_tensor(y_test)
train_masks = tf.convert_to_tensor(train_masks)
test_masks = tf.convert_to_tensor(test_masks)
train_dataset = tf.data.Dataset.from_tensor_slices(((X_train, train_masks), y_train)).batch(8)
test_dataset = tf.data.Dataset.from_tensor_slices(((X_test, test_masks), y_test)).batch(8)
아래와 같이 tensor인 input_ids, attention_masks를 numpy array로 변환하고
train_test_split을 사용하여 분할한 이후에
분할된 데이터들을 일일이 tensor로 다시 변환해 주니 정상적으로 작동했다.
'python > MLDL' 카테고리의 다른 글
| kaggle Spooky Author Identification 상위99% (2) | 2024.06.07 |
|---|---|
| Cross Entropy, Categorical Cross Entropy, Sparse Categorical Cross Entropy (0) | 2024.06.05 |
| GPT에게 배우는 클러스터링의 종류, 장단점과 사용처 (0) | 2024.05.27 |
| GPT에게 자연어처리 배우기(문자열 전처리) (0) | 2024.05.24 |
| GPT에게 자연어처리 배우기(모델 구현) (0) | 2024.05.24 |

