보통 log손실함수 값이 0.0n이 나오는 도전과제에서 자랑스럽게 1점대를 기록했다.
거의 꼴찌에 가까운 점수인것같다.
처음 피드포워드 모델을 구현해서 도전과제에 도전하고 다른 선발대 분들의 노트북을 봤을 때 성능 좋은 모델들을 사용하여 고득점을 받아내는 경우가 많았다.
이 과정에서 XGBoost, Randomforest 의 존재를 알았기에 nlp 문제도 요즘 기가막힌다는 transfomers bert 모델을 파인튜닝 해서 접근했다.
문자열 데이터 전처리, 모델의 구현방법은 알았지만 문제가 있었다.
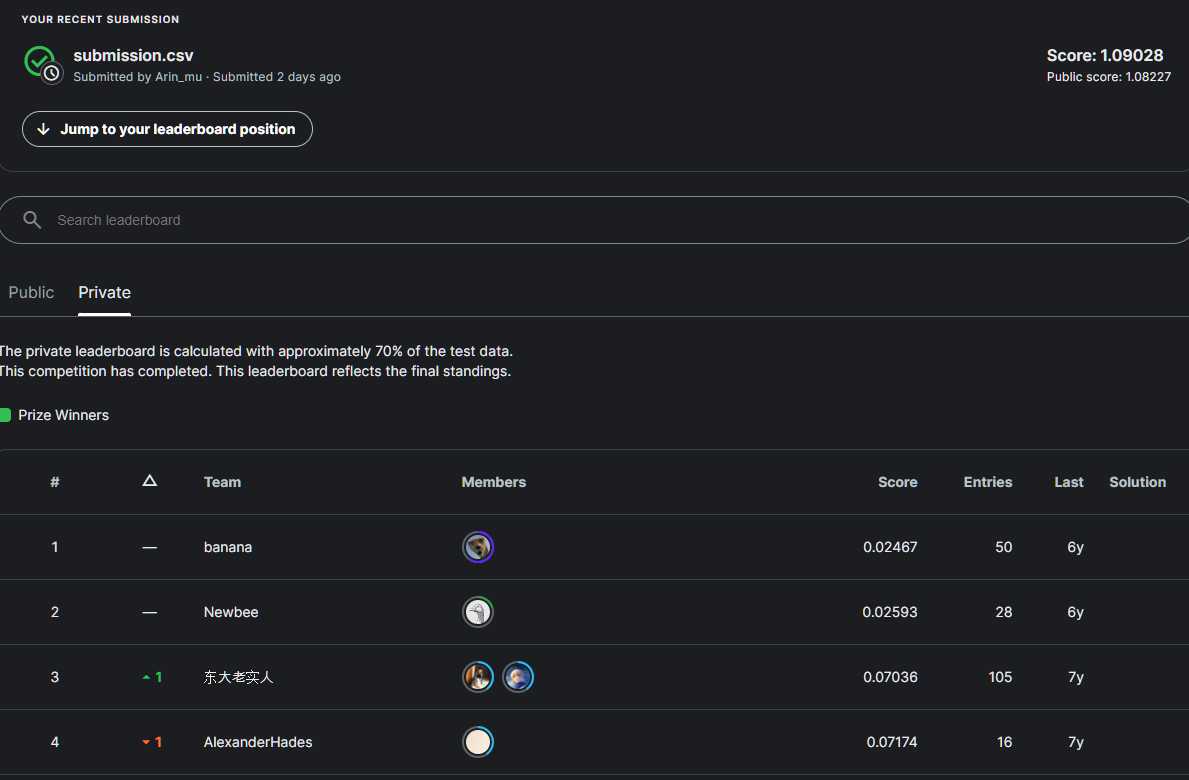
처음에 그냥 파인튜닝해서 예측한걸 출력했을때 logloss값이 0.2, accuracy는 82%가 나왔는데 제출이 되지 않아 살펴보니 원시점수로 출력되었다.
원시점수가 뭔가 하고 봤더니 확률로 변환하기 전에 모델이 각 클래스에 대해 계산한 점수라고 한다.
이를 적절한 활성함수가 사용된 레이어를 통해 변환해주어야 한다고 한다.
이걸 모르고
loss = tf.keras.losses.CategoricalCrossentropy(from_logits=False)모델 구현하는 코드의 일부인데 loss함수값을 명시해주는 과정에서 from_logits= << 이곳이 문제인 것 같아 False만 주고 했을때도 원시점수만 출력하여 GPT에게 물어봤다.


아...
True를 주면 확률 형태로 출력이 아니라 내부적으로 알아서 계산해서 출력해주기에 내가 보고 판단할 수 있지만 어디 제출하거나 결과를 또 다른 형태로 활용하려면 추가적인 처리가 필요한 것 같다.
False를 주었을땐 그냥 내부적인 계산도 안하고 빠르게 효율적으로 원시점수로 출력해버리는것같다.
결국 이번 케이스 같은 경우에는 확률이 필요하기에 활성함수에 softmax를 사용한 레이어가 필요했다.
GPT의 도움과 여러번의 수정 끝에 tiny bert를 파인튜닝한 것을 피드포워드 모델과 결합하는데 성공했다.
# 입력 레이어 정의
input_ids_layer = tf.keras.layers.Input(shape=(128,), dtype=tf.int32, name='input_ids')
attention_mask_layer = tf.keras.layers.Input(shape=(128,), dtype=tf.int32, name='attention_mask')
# 람다 레이어를 사용하여 TFBertForSequenceClassification 래핑
def bert_model(inputs):
input_ids, attention_mask = inputs
outputs = base_model(input_ids, attention_mask=attention_mask)
return outputs.logits
logits = tf.keras.layers.Lambda(bert_model, output_shape=(3,))([input_ids_layer, attention_mask_layer])
dense_layer = tf.keras.layers.Dense(3, activation='linear')(logits)
probabilities = tf.keras.layers.Activation('softmax')(dense_layer)
model = tf.keras.Model(inputs=[input_ids_layer, attention_mask_layer], outputs=probabilities)전처리한 데이터를 입력으로 받고 그 데이터들이 bert를 통해 cls 토큰을 원시점수로 변환한 후 bert 모델의 출력을dense_layer를 통해 3개로 줄여주었다.
그리고 softmax 활성함수가 사용된 layer를 통해 3개의 클래스를 확률로 변환해주었다.
그런데 사실 이번 문제에서 dense_layer의 존재 이유와 정확한 역할을 이해하지 못해서 GPT에게 다시한번 물어보고 깨달았다.
#손실함수 정의할 때 from_logits=False를 한 경우
output = layer.Dense(3, activation='softmax')(cls_token)이렇게 층 하나를 줄여서 사용할 수 있고,
True를 준다면 무슨일이 있어도 다른 활성함수를 사용하지 않으면 그냥 원시점수를 내뿜기에
nlp 할 때 원시점수가 필요하다 > from_logits = True
nlp 할 때 원시점수가 아닌 다른 활성함수를 통한 값이 필요하다 > from_logits = False 사용
왜 1이 넘게 나왔는가 고민해 보았다.
원인 1. 학습 데이터에 비해 tiny bert 모델이 거대했다.
원인 2. 출력 차원 축소 과정에서 과적합이 일어났다.
1번은 LSTM과 같은 전통적인 방법을 사용해 봐야겠다.
2번은 차원 축소를 바로 3개로 줄이는것이 아닌 여러개의 층으로 drop out을 줘가면서 해야봐야겠다.
'python > MLDL' 카테고리의 다른 글
| Cross Entropy, Categorical Cross Entropy, Sparse Categorical Cross Entropy (0) | 2024.06.05 |
|---|---|
| Spooky Author Identification (클러스터링, PCA) (0) | 2024.06.04 |
| GPT에게 배우는 클러스터링의 종류, 장단점과 사용처 (0) | 2024.05.27 |
| GPT에게 자연어처리 배우기(문자열 전처리) (0) | 2024.05.24 |
| GPT에게 자연어처리 배우기(모델 구현) (0) | 2024.05.24 |

